
Strukturálatlan dokumentumfeldolgozási stratégiák
Meglátásunk szerint három különböző megközelítést érdemes figyelembe venni, amikor strukturálatlan dokumentumok feldolgozására keresünk megoldást:
- Felhőalapú dokumentumfeldolgozási szolgáltatások
- Saját fejlesztésű nagy nyelvi modellek (LLM-ek)
- Nyílt forráskódú nagy nyelvi modellek (LLM-ek)
Felhőalapú dokumentumfeldolgozási szolgáltatások
A felhőszolgáltatók speciális eszközöket kínálnak az adatok kinyerésére, például:
- AWS (Textract)
- Azure (AI Document Intelligence)
- Google (Document AI)
Ezek a megoldások hasonlóak, mind rendelkeznek számos beépített funkcióval, mint például az OCR (optikai karakterfelismerés), táblázatok kinyerése és szűrők, továbbá alapértelmezés szerint többféle dokumentumformátumot is támogatnak. Nincs lehetőség arra, hogy a saját szerverinken használjuk, az integrációhoz API használatára van szükség, így a forrásdokumentumokat a felhőbe kell feltölteni.
Előnyök:
- Könnyű indulás
- Pontosság
- Méretezhetőség
- Nincs szükség helyi szerverinfrastruktúrára
Hátrányok:
- Szolgáltatótól való függőség
- Korlátozott rugalmasság
- Adatvédelemmel kapcsolatos aggályok
Saját fejlesztésű nagy nyelvi modellek (LLM-ek)
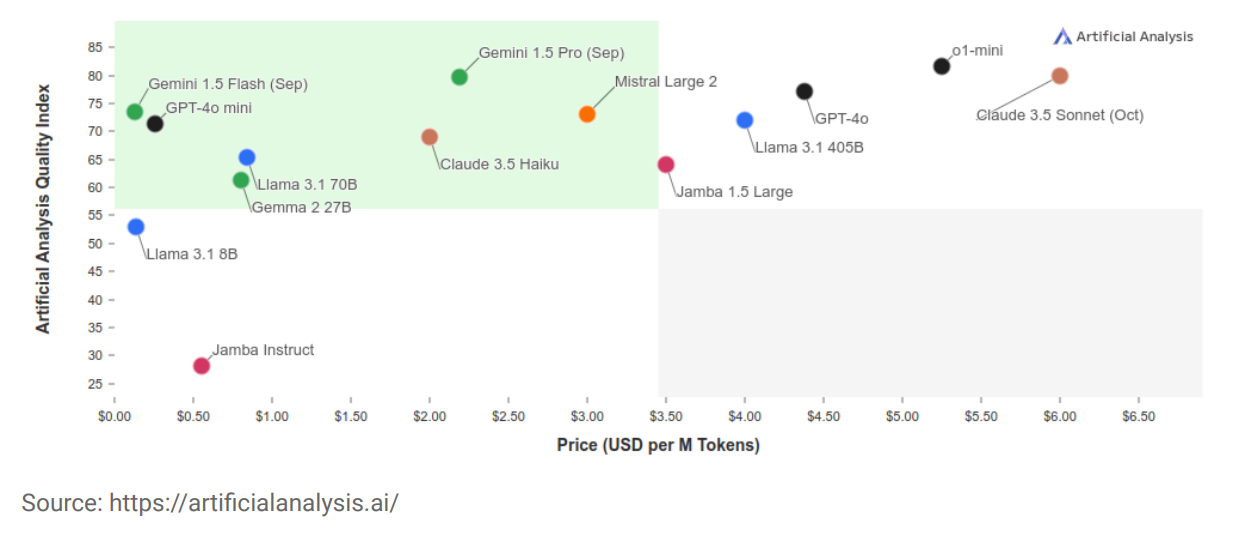
Az ismert AI-szolgáltatók API-kon keresztül kínálnak hozzáférést nagy nyelvi modelljeikhez. Ebben a megközelítésben a dokumentumot előkészítés után az API-n keresztül kell beküldeni, a feldolgozás pedig a szolgáltató infrastruktúrájában történik.
Saját fejlesztésű LLM-ek:
- OpenAI GPT
- Anthropic Claude
- Google Gemini
- Mistral AI
Az OpenAI használatát javasoljuk, mivel jelenleg ez a legkorszerűbb AI-megoldás a piacon. Az OpenAI a Microsoft Azure adatközpontjait használja, lehetőséget kínál az adatmegőrzés kizárására, és igény esetén EU-s adatközpontok is elérhetők.
Előnyök:
- Rugalmasság
- Jobb kontextusértés
- Gyors modellfejlesztés
- Multimodalitás (szöveg és kép bemenet támogatása)
- További funkciókhoz is használható, például ügyfélszolgálati chatbotokhoz
- Nincs szükség helyi szerverinfrastruktúrára
Hátrányok:
- Adatvédelemmel kapcsolatos aggályok, a forrásdokumentumokat a szolgáltatóhoz kell feltölteni
- Szolgáltatótól való függőség (bár az OpenAI API-ját sok más LLM is használja)
- „Fekete doboz” működés
Nyílt forráskódú nagy nyelvi modellek (LLM-ek)
A nyílt forráskódú nagy nyelvi modellek olyan generatív AI-megoldások, amelyek helyben telepíthetők és továbbfejleszthetők. Az alapmodell alapos kezdeti képzéssel rendelkezik, amely lehetővé teszi a kontextus megértését, miközben specifikus célokra is finomhangolható.
Nyílt forráskódú/weights LLM-ekre néhány példa:
- Meta Llama
- Google Gemma
A Meta Llama modellt ajánljuk, amely gyorsan fejlődik, és multimodális képességekkel rendelkezik (a Llama3.2 például képeket is képes feldolgozni).
Előnyök:
- Nincsenek adatvédelmi aggályok
- Nincs szolgáltatótól való függőség
- Egyedi megoldás hosszú távon a modell továbbképzésével
- Kódbázis átláthatósága
- Teljes kontroll az adatok fölött
Hátrányok:
- Magasabb kezdeti költségek a helyi szerverinfrastruktúra miatt
- A pontosság a modell méretétől függ; nagyobb modellhez komoly szerverteljesítmény szükséges
- Korlátozott méretezhetőség
- A szerverek kihasználtsága szélsőségesen változó, nem optimális
Következtetés
Az AI-modellek teljesítményét egy adott felhasználási esetben nehéz előre megjósolni. Egyrészt a modellek rendkívül összetettek és nem-determinisztikusak, másrészt a bemeneti PDF-dokumentumok is heterogének lehetnek: némelyek szkennelt formátumúak, és a formázásuk is eltérő. Figyelembe kell venni, hogy ez a terület nagyon gyorsan változik, ezért nem célszerű hosszú távon egyetlen szállító vagy megoldás mellett elköteleződni.
Véleményünk szerint törekedni kell arra, hogy a nyelvi modellt könnyen cserélhető módon integráljuk, így az újabb verziók vagy fejlettebb modellek megjelenésekor azok előnyeit egyszerűbben kiaknázhatjuk, csökkentve ezzel a szállítókhoz való kötöttséget. Részletes tanácsaadásért forduljon Semantic AI üzletágunkhoz.
Kenéz András, Fejlesztési Vezető
Strukturálatlan dokumentumfeldolgozási stratégiák
Meglátásunk szerint három különböző megközelítést érdemes figyelembe venni, amikor strukturálatlan dokumentumok feldolgozására keresünk megoldást:
- Felhőalapú dokumentumfeldolgozási szolgáltatások
- Saját fejlesztésű nagy nyelvi modellek (LLM-ek)
- Nyílt forráskódú nagy nyelvi modellek (LLM-ek)
Felhőalapú dokumentumfeldolgozási szolgáltatások
A felhőszolgáltatók speciális eszközöket kínálnak az adatok kinyerésére, például:
- AWS (Textract)
- Azure (AI Document Intelligence)
- Google (Document AI)
Ezek a megoldások hasonlóak, mind rendelkeznek számos beépített funkcióval, mint például az OCR (optikai karakterfelismerés), táblázatok kinyerése és szűrők, továbbá alapértelmezés szerint többféle dokumentumformátumot is támogatnak. Nincs lehetőség arra, hogy a saját szerverinken használjuk, az integrációhoz API használatára van szükség, így a forrásdokumentumokat a felhőbe kell feltölteni.
Előnyök:
- Könnyű indulás
- Pontosság
- Méretezhetőség
- Nincs szükség helyi szerverinfrastruktúrára
Hátrányok:
- Szolgáltatótól való függőség
- Korlátozott rugalmasság
- Adatvédelemmel kapcsolatos aggályok
Saját fejlesztésű nagy nyelvi modellek (LLM-ek)
Az ismert AI-szolgáltatók API-kon keresztül kínálnak hozzáférést nagy nyelvi modelljeikhez. Ebben a megközelítésben a dokumentumot előkészítés után az API-n keresztül kell beküldeni, a feldolgozás pedig a szolgáltató infrastruktúrájában történik.
Saját fejlesztésű LLM-ek:
- OpenAI GPT
- Anthropic Claude
- Google Gemini
- Mistral AI
Az OpenAI használatát javasoljuk, mivel jelenleg ez a legkorszerűbb AI-megoldás a piacon. Az OpenAI a Microsoft Azure adatközpontjait használja, lehetőséget kínál az adatmegőrzés kizárására, és igény esetén EU-s adatközpontok is elérhetők.
Előnyök:
- Rugalmasság
- Jobb kontextusértés
- Gyors modellfejlesztés
- Multimodalitás (szöveg és kép bemenet támogatása)
- További funkciókhoz is használható, például ügyfélszolgálati chatbotokhoz
- Nincs szükség helyi szerverinfrastruktúrára
Hátrányok:
- Adatvédelemmel kapcsolatos aggályok, a forrásdokumentumokat a szolgáltatóhoz kell feltölteni
- Szolgáltatótól való függőség (bár az OpenAI API-ját sok más LLM is használja)
- „Fekete doboz” működés
Nyílt forráskódú nagy nyelvi modellek (LLM-ek)
A nyílt forráskódú nagy nyelvi modellek olyan generatív AI-megoldások, amelyek helyben telepíthetők és továbbfejleszthetők. Az alapmodell alapos kezdeti képzéssel rendelkezik, amely lehetővé teszi a kontextus megértését, miközben specifikus célokra is finomhangolható.
Nyílt forráskódú/weights LLM-ekre néhány példa:
- Meta Llama
- Google Gemma
A Meta Llama modellt ajánljuk, amely gyorsan fejlődik, és multimodális képességekkel rendelkezik (a Llama3.2 például képeket is képes feldolgozni).
Előnyök:
- Nincsenek adatvédelmi aggályok
- Nincs szolgáltatótól való függőség
- Egyedi megoldás hosszú távon a modell továbbképzésével
- Kódbázis átláthatósága
- Teljes kontroll az adatok fölött
Hátrányok:
- Magasabb kezdeti költségek a helyi szerverinfrastruktúra miatt
- A pontosság a modell méretétől függ; nagyobb modellhez komoly szerverteljesítmény szükséges
- Korlátozott méretezhetőség
- A szerverek kihasználtsága szélsőségesen változó, nem optimális
Következtetés
Az AI-modellek teljesítményét egy adott felhasználási esetben nehéz előre megjósolni. Egyrészt a modellek rendkívül összetettek és nem-determinisztikusak, másrészt a bemeneti PDF-dokumentumok is heterogének lehetnek: némelyek szkennelt formátumúak, és a formázásuk is eltérő. Figyelembe kell venni, hogy ez a terület nagyon gyorsan változik, ezért nem célszerű hosszú távon egyetlen szállító vagy megoldás mellett elköteleződni.
Véleményünk szerint törekedni kell arra, hogy a nyelvi modellt könnyen cserélhető módon integráljuk, így az újabb verziók vagy fejlettebb modellek megjelenésekor azok előnyeit egyszerűbben kiaknázhatjuk, csökkentve ezzel a szállítókhoz való kötöttséget. Részletes tanácsaadásért forduljon Semantic AI üzletágunkhoz.
Kenéz András, Fejlesztési Vezető
